There is a growing trend in organizations to solve everything with Microservices. For a lot of modern-day applications still, a single node monolith is enough and a better choice. Microservices are not a silver bullet which will solve all our technical problems. It comes with its own baggage which has to be taken into consideration and is neatly explained by Martin Fowler here. Increased operational complexity in using Microservices is certainly an area of concern but it is a solvable problem. In order to handle the operational complexity one of the major concern while doing microservices, we need to get more insights about services, the time taken to complete a request, how they communicate with each other and so on. Importance of tracing in distributed systems have produced a lot of thought process among the development teams and Google's Dapper paper has influenced one such amazing tracing library called Zipkin. Zipkin library has support for most of the widely used programming languages and is one of the most actively contributed open source projects. I happened to meet Adrian Cole one of the Zipkin's core contributor who has shed more light on the importance of the tracing even though I have been using it for a while. You can also watch this amazing video to know more about the importance of Distributed Tracing.
Spring Cloud suite of libraries has one more powerful tool in their arsenal called Spring Cloud Sleuth (very apt name indeed). We are going to use Spring cloud Sleuth which works seamlessly with Zipkin. Sleuth will instrument the ingress and egress points in your application, collect Zipkin compatible traces (if Zipkin available) and sends to the Zipkin collector.
Zipkin Architecture
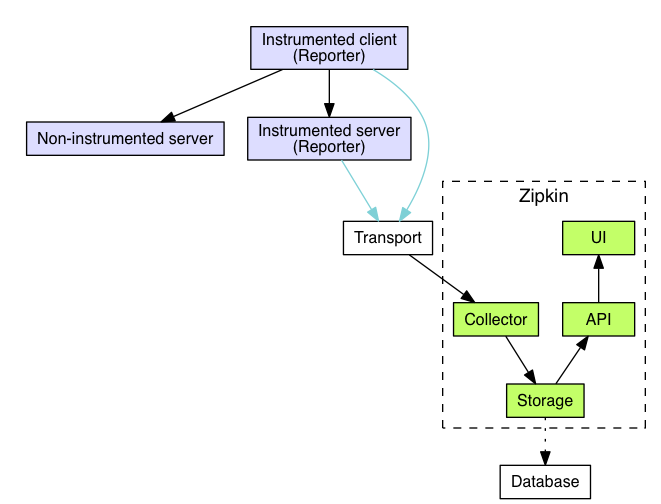
Zipkin Architecture, Image Source: http://zipkin.io/
Let's see the setup of our example application. It has four services, the Gateway service which proxy the request to the downstream bookservice. The gateway service gets the available book services with the help of Eureka which is our service discovery. All the three services will send the traces to Zipkin server with the help of Spring cloud Sleuth.

Go to http://start.spring.io and select the Eureka server and import the project into your favorite IDE either STS or IntelliJ IDEA (now you can start using VS Code as well I hear). Open the class which contains the main method and annotate it with @EnableEurekaServer
Now open your application.yml file add the below lines which will make the discovery server not to register itself.
[cc lang="java"]
eureka:
client:
register-with-eureka: false
fetch-registry: false[/cc]
We will be creating our core application service which is called bookservice. It will use MongoDB as a persistent layer to store the book documents. You can either use standalone installation or a MongoDB docker image and the application can be bootstrapped anywhere of your choice. Our service will have one Entity called Book.
[cc lang="java"]@Data
@Document(collection = "books")
public class Book {
@Id
private String id;
private String title;
private String author;
}[/cc]
We will have a create a repository interface to communicate with the MongoDB and we will call it a BookRepository which will extend obviously MongoRepository. Controller is an implementation of RestController which will contain one endpoint at the moment to retrieve all the books
[cc lang="java"]
//BookRepository.java
@Repository
public interface BookRepository extends MongoRepository<Book, String> {
}
[/cc]
[cc lang="java"]
// BookController.java
@RestController
public class BookController {
@Autowired
BookRepository repository;
@GetMapping(path = "/books")
public ResponseEntity<List> getBooks() {
return new ResponseEntity<List>(repository.findAll(), HttpStatus.OK);
}
}[/cc]
Next create our Gateway server like the\same way from start.spring.io and annotate the class with the main method with @EnableZuulProxy and @EnableEurekaClient. And the below configuration attributes to route the bookservice which we have created.
[cc lang="java"]
zuul:
routes:
bookservice:
path: /bookservice/**
serviceId: bookservice [/cc]
Run all the three services and you should see that the Gateway server and Bookservice registered at Eureka. Let's test the application by invoking the bookservice via Zuul proxy.
[cc]curl -v http://localhost:8765/bookservice/books | json_pp[/cc]
Here comes the important part of this post. Our whole idea was to instrument our services and understand them better. We have to include Spring Cloud starter Zipkin in all three services.
[cc lang="groovy"]
compile('org.springframework.cloud:spring-cloud-starter-zipkin')[/cc]
Sleuth generates unique trace and span ids (64 bit by default and 128 bit is also supported). A span is a smallest basic unit of work which can an RPC call to a remote service. One or more spans form a trace. Generated spans will be sent to the Zipkin server which we are going to create next.
Zipkin server can be created in multiple ways, you can clone the repo, compile and run it. If you would like run it as a docker container which is also available at docker hub. But we are going to run it as a Springboot application and for that, you need to include two artifacts one is a zipkin server and another one is zipkin ui.
[cc lang="groovy"]compile('io.zipkin.java:zipkin-server:2.3.1')
runtime('io.zipkin.java:zipkin-autoconfigure-ui:2.3.1')[/cc]
Important Update:
Starting from recent Zipkin release, the preferred or recommended way of using Zipkin Server is to use the official Zipkin jar released by the team instead of making your own server or the official docker image.[cc]curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jardocker run -d -p 9411:9411 openzipkin/zipkin[/cc]
Once you start the Zipkin server, navigate to http://localhost:9411/zipkin and you should be seeing the list of services, traces, and spans.
We will use the in-memory storage to store the traces but we can also specify the data store of our choice which we want to use by specifying in the application.yml.
[cc lang="java"]
zipkin:
storage:
type: mysql[/cc]
By default sleuth with zipkin uses HTTP to transport the traces but you can also stream the traces either via RabbitMQ and Kafka.
As always the entire code base is available in the Github.

Great article!
compile('org.springframework.cloud:spring-cloud-starter-sleuth')
compile('org.springframework.cloud:spring-cloud-starter-zipkin')
it’s enough to provide only the Zipkin starter (https://github.com/spring-cloud/spring-cloud-sleuth/blob/v1.3.0.RELEASE/spring-cloud-starter-zipkin/pom.xml#L18-L21) cause the other one will be automatically picked.
Thank you, Marcin. I have modified it.
Informative Sundar
Thanks you for this article, i am looking to delete automatically stored traces in MySQL, is there a way to do this in spring cloud sleuth ?
This has nothing to do with Spring Cloud Sleuth. Only with Zipkin since the spans are stored there. I have no knowledge of such a mechanism but if you ask about this on Zipkin Gitter channel for sure someone will help you.
For better understanding. I have updated the post with the Zipkin Architecture.